node2vec的论文地址:node2vec: Scalable Feature Learning for Networks
node2vec跟deepwalk的大体框架一样,都是通过随机游走在graph上生成序列,然后使用skip-gram的方法得到这些节点的embedding。但不同的是node2vec的随机游走策略不同。我们先来看一下我们期望的节点的embedding拥有的两大特性,如图

- 趋同性。两个越相近的节点,它们的embedding vector越相近,比如节点$u$和节点$s_1$。
- 角色等价性。两个在子图或者说社交圈中角色越相近的节点,它们的embedding vector越相近,比如节点$u$和$s_6$都是扮演中心枢纽的角色。
图中展示了两种极端的游走策略,广度优先遍历(BFS)和深度优先遍历(DFS)。其中BFS关注每个节点的邻居,它使得embedding vector具有角色等价性;而DFS使得embedding vector具有趋同性。而node2vec融合了这两种游走策略。
通常对于有权值的图来说,游走策略为
其中$c_i$表示第$i$选取的节点,$\pi_{vx}$为权值或者说是非标准化的选取概率,$Z$为标准化常量。比如上图中,假如节点$u$和$s_1$,$s_2$,$s_3$,$s_4$的之间的权值分别为1,2,3,4,那么$P(c_i = s_1 \mid c_{i-1} = u) = \frac{1}{10}, P(c_i = s_2 \mid c_{i-1} = u) = \frac{2}{10}, P(c_i = s_3 \mid c_{i-1} = u) = \frac{3}{10}, P(c_i = s_4 \mid c_{i-1} = u) = \frac{4}{10}$。
而node2vec引入两个参数 p 和 q,非标准化的选取概率计算方式为
其中$w_{vx}$为节点$v$和节点$x$之间的权值,$\alpha_{pq}(t,x)$的计算方式为
其中$d_{tx}$表示节点$t$和节点$x$之间的最小距离,取值只能是{0,1,2}。如下图
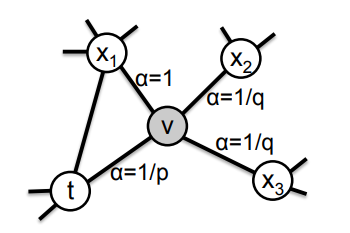
$d_{tx}$可以理解为节点的邻居们之间的距离,$t$和$x$都是邻居。如图我们需要在邻居中选取一个基准节点$t$,那么四个邻居$t$, $x_1$, $x_2$, $x_3$的 $d_{tx}$值分别为0,1,2,2, 所以$\alpha_{pq}$值分别为$\frac{1}{p}$,$1$,$\frac{1}{q}$,$\frac{1}{q}$。
我们直观地来理解一下$p$和$q$这两个参数。p称之为return parameter(回溯参数),p值越小,也就越容易游走到$d_{tx}$值为0的邻居节点,如图容易从$v$到$t$,然后再从$t$到$v$,容易回溯到已经走过的节点;p值越大,越不容易走到已经走过的节点。q称之为in-out parameter(局部参数),q值越小,也就越容易游走到$d_{tx}$值为2的节点,距离为2说明这个节点里邻居比较远,说明越容易走出局部区域,这样的行为对应于DFS;反之q值越大,越容易在局部游走,行为对应于BFS。
我们分析一下复杂度。空间复杂度,存储每个节点的邻居,也就是度数和为O(|E|),还要存储邻居之间的距离为O($\alpha^2$|V|),其中$\alpha$为平均邻居数,这个值通常很小。时间复杂度,如果skip-gram的窗口为k,我们可以采样一条长度为l > k的路径,这样就相当于采样了l-k个样本,重用该路径,虽然有一些偏差,但可以提高效率。
node2vec的算法步骤为:

论文中还提到了link prediction(边预测),我们知道了两个节点$u$和$v$的embedding vector,如何预测这两个节点之间是否存在连接,文章是对这两个节点的embedding vector进行一些二进制操作得到节点对或者说是边的embedding vector,文中提到了以下方法