上一张我们学习了如何应用动态规划解决强化学习问题,但是这是在MDP所有信息已知的情况下,如果不知道环境信息,我们该如何解决预测和控制问题呢?这章我们先来解决无环境信息的预测问题,称之为Model-Free Prediction。
Model-Free Prediction
Model-Free Prediction实际上是对未知环境MDP的值函数进行评估,主要有Monte-Carlo Learning(蒙特卡洛学习)、Temporal-Difference Learning(时间差分学习)、Temporal-Difference Lambda(时间差分学习的扩展)。
Monte-Carlo Learning
特色:
- 蒙特卡洛方法直接从经验片段中学习
- 蒙特卡洛方法是model-free的,也就是不知道MDP的状态转移矩阵和奖励函数
- 蒙特卡洛方法需要从完整的经验片段中学习
- 蒙特卡洛方法采用最简单的想法:值函数值 = 回报的均值
- 蒙特卡洛方法只能应用到有回合制的MDP中,也就是你的所有经验片段必须能够终止
蒙特卡洛方法如何进行策略评估呢?
- 目标:从按照策略 $\pi$ 得到的经验片段中学习 $v_\pi$
- 回报的定义是折扣奖励和
- 值函数的定义是回报的期望
- 蒙特卡洛策略评估方法采用经验回报的均值来替代回报期望
我们已经知道用经验回报的均值来表示回报期望,假如我们用(S,R)元组来表示状态-即时奖励对,有一个经验片段为 (A, 3), (B,4), (C,3), (A, 5), (D,4). 那么我们怎么计算状态A的回报呢?是以第一次A开始算还是以第二次A开始算呢?有两种方法来计算,一种是以每个状态第一次出现开始计算,后面出现的忽略,这个片段对于状态A,回报为 $G = 19$ ;另一种方法是每个状态每次出现都作为一次,这个片段对于状态A,会计数两次,一次回报为 $G = 19$,另一次回报为 $G = 9$。
下面介绍一种增量式的平均值计算方法,这个方法非常重要, 后面经常用到,假如有一个序列 $x_1, x_2, \cdots, $
他的均值依次为:
我们可以用增量式的方法来依次计算
那么均值依次为:
采用增量式的均值计算方法,蒙特卡洛方法的步骤为:
- 根据策略 $\pi$ 生成经验片段
- 将经验片段处理成 $\left( S_t, G_t \right)$ 状态-回报对
- 对所有的$\left( S_t, G_t \right)$
这里更新式通常写作
在机器学习中,这个 $\alpha$ 通常称之为学习率,这里也是这个意思,不过我们可以直观的理解,当学习很久以前的经验片段,我们让学习率变小,也就是让时间距离久的经验起小一点的作用,当学习近期的经验片段,我们让学习率变大,也就是让时间距离近的经验起大一点的作用,这样看来 $\alpha$ 就是用来控制学习的速率的。
Temporal-Difference Learning
特色:
- 时间差分方法直接从经验片段中学习
- 时间差分方法是无模型的,也就是不知道MDP的状态转移矩阵和奖励函数
- 时间差分方法可以从不完整的经验片段中学习
- 时间差分方法更新一个猜测基于另一个猜测(这是英文直译,后面自然会明白)
蒙特卡洛学习方法与时间差分学习方法的差异:
目标:都是从按照策略 $\pi$ 生成的经验片段中学习值函数 $v_\pi$
更新公式:
- 蒙特卡洛方法: $V(S_t) \leftarrow V(S_t) + \alpha (G_t - V(S_t))$
- 时间差分方法: $V(S_t) \leftarrow V(S_t) + \alpha (R_{t+1} + \gamma V(S_{t+1}) - V(S_t))$
其中 $R_{t+1} + \gamma V(S_{t+1})$ 被称之为TD目标 $\delta_t = R_{t+1} + \gamma V(S_{t+1}) - V(S_t)$ 被称之为TD误差
蒙特卡洛方法和时间差异方法的优劣:
- TD可以在每一步中学习(在线学习),而MC必须等到片段结束才能学习
- TD可以从不完整的片段中学习, 而MC只能从完整的片段中学习
- TD可以在没有终止状态(连续)的MDP环境中工作,而MC只能在有终止状态(回合制)的MDP环境中工作
- 回报 $G_t = R_{t+1} + \gamma R_{t+2} + \cdots + \gamma^{T-1}R_T$ 是 $v_\pi(S_t)$ 的无偏估计, 而TD目标 $R_{t+1} + \gamma V(S_{t+1})$ 却是 $v_\pi(S_t)$ 的有偏估计
- TD目标比回报的方差低,因为回报依赖多个随机行为、转移、奖励,而TD目标值依赖一个随机行为、转移和奖励
- MC高方差,无偏差;TD低方差,一些偏差。
- MC有好的收敛性,对初始值不太敏感,非常简单理解和使用;TD通常比MC更有效率,对初始值更敏感
- MC拟合经验数据,而TD拟合MDP
- MC不利用马尔可夫属性,通常在非马尔可夫环境中更高效;TD利用马尔可夫属性,通常在马尔可夫环境中更高效
Temporal-Difference lambda
TD($\lambda$)是在TD上的扩展,试想,如果我们TD目标向前看n步,如果n足够大,那么TD实际上就变成了MC方法

我们定义n-step回报为:
n-step的时间差分方法更新式为
当n = 1时就是普通的TD方法,当n趋于无穷大时就是MC方法,自然就萌生了一个想法,能不能将这两个优点结合起来呢?使用加权平均来将这些回报结合起来。
前面的系数是为了保证权值和为1.
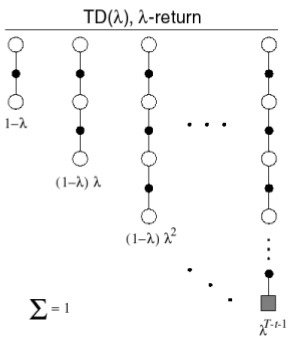

所以TD($\lambda$)的更新公式为
原教程中将这种TD lambda称之为前向的观点,还有后向的观点,这里不在叙述,有兴趣的请移步原教程ppt。