之前一直打算学习一下强化学习,也看了一些教程,比如西瓜书《机器学习》上的强化学习教程,但学完发现公式非常复杂,给人一种非常痛苦的感觉,再比如莫凡强化学习教程,一开始就有点云里雾里的感觉,感觉这个教程是需要一定的强化学习基础,再去学就好多了。
最近找到了口碑不错的一个教程,是出自David Sliver的,这位大神是来自DeepMind团队的,教程深入浅出,是我目前看到的入门强化学习最好的教学,教学资源请点击这里,里面包括ppt和英文视频,网友也有中文版的视频翻译,不过有些地方翻译的不太准确,不过配合ppt看的话,也还能看。如果你想学习这份教程,我有以下几点建议:
- 如果你的英文水平不错的话,建议直接观看原英文视频,并在看完是视频后过一遍ppt
- 如果你的英文水平看英文视频吃力的话,建议先认真的看一遍ppt,然后带着问题去看中文视频
- 教学视频共10段,每段大概一个小时四十分钟左右,可能较为耗时,如果你的时间不太充足,建议直接观看我的学习笔记,最后如果还感觉不太清楚,可以过一遍ppt。
我终于用了一个星期左右的时间看完了这个教程,这里相当于是一个学习笔记,主要内容是按照这个教程的ppt走的,可能会加一些自己的理解,如果有哪里不对的欢迎讨论。
简介
强化学习在不同的领域有不同的表现形式:

强化学习是机器学习的一个分支,机器学习包括:监督学习、非监督学习、强化学习。

强化学习的特点:
- 无监督的,只有奖励信号
- 奖励反馈是延迟的,不是及时的
- 时间序列很重要(数据是序列的,并不是独立同分布[i.i.d]的数据)
- 代理的行为会影响它接收到的后续数据
强化学习的例子:
- 直升飞机特技
- 在Backgammon游戏中打败世界冠军(还有最近的AlphaGo)
- 管理投资组合方式
- 控制发电站
- 控制机器人走路
- 在很多不同的Atari游戏上超越了人类
基础概念
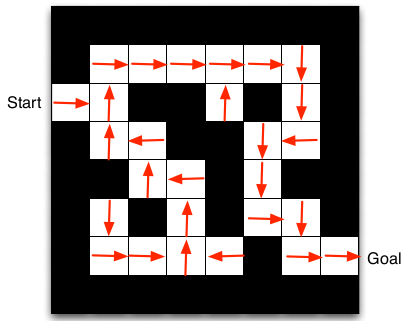
这里用一个例子来阐述相关基础概念,如下图是一个迷宫,白色方块表示可以通行,黑色方块表示不能通行。start旁边的方格表示迷宫入口,Goal旁边的方格表示出口。

奖励(Reward)
- 奖励是一个标量反馈信号
- $R_t$表明代理(Agent)在第t步做的有多好
- 代理的工作就是最大化累积奖励(也就是我最大化我的整个过程中的奖励和,而不是最大化某一步的奖励)
奖励假设的定义:强化学习中所有的目标都可以描述为最大化累积奖励的期望。奖励假设是强化学习的根基。
序列决策的制定:
- 目标:选择行为来最大化未来总奖励
- 行为可能有长期的影响
- 奖励可能延迟
- 有时牺牲短期的奖励会更好,以此来获取长期的奖励
迷宫的例子中每走一步的奖励都是-1,因为我们想通过最少的格子走出迷宫,比如通过十个格子走出,比通过十一个格子走出要好,我们通过这种奖励设定来鼓励代理寻找最优的策略。
这是个特例,其他的例子中奖励可能会根据不同的状态下作出不同的动作而有所不同,并不全是-1。有的任务中奖励可能是明确的,比如打飞机游戏中,打掉一个飞机多少分数,打掉一个boss多少分数,而这个奖励以及打掉飞机和打掉boss的奖励相对大小都是根据游戏的宗旨(努力存活更久)制定的,而现实中我们要解决的任务中,可能需要我们自己去根据任务目标和不明确的反馈来制定奖励函数。这里举一个例子,比如百度搜索排序任务中,用户在搜索结果中点击排在第一的item和点击排在第二的item奖励显然不同,或者点击搜索结果第二页的item,奖励也不同,这就需要我们根据这些不明确的反馈来制定奖励函数。后面有机会再介绍工业上强化学习的运用。
代理(Agent)和环境(Environment)
强化学习的过程实际就是一个代理和环境交互的过程。
在第t步,代理:
- 执行动作$A_t$
- 收到观察$O_t$
- 收到奖励$R_t$
环境:
- 收到动作$A_t$
- 呈现观察$O_{t+1}$
- 反馈奖励$R_{t+1}$

比如迷宫例子中,代理就是你,环境就是这个网格,我们使用强化学习的过程:
在第t步,你:
- 执行动作(向上,向下,向左,向右)
- 收到观察(现在所处的位置)
- 收到奖励(-1)
网格环境:
- 收到动作指令
- 呈现观察(比如向上,就呈现上移一格的观察)
- 反馈给你奖励(每走一步-1)
历史(History)和状态(State)
历史指的是观察(Observation)、动作(Action)、奖励(Reward)的序列
状态包含来自历史中有用的信息,正式的讲,状态是历史的函数:
由于环境的是否可完全观测,状态分为完全观察状态和部分观察状态。
比如迷宫的例子中,我们先区分一下历史(History)、观察(Observation)、状态(State),这里观察指的是位置,我们用一个元组(行数,列数)表示,比如start位置观察为(2,1),这里奖励为-1,这里历史指的是我们走了一段路程后
那么状态呢?因为状态是历史的函数,对于第t+2步,我们可以说
或者
甚至
看哪个对问题有利,就采用哪个,状态决定了你接下来的动作,是下面一讲中的马尔科夫中的重要概念,所以很重要。这个例子中我们选择第一种就够了。
至于完全观察状态和部分观察状态,在这里,比如我们对于位置得不到完全信息,只观察到列的信息,无法观察到行的信息。
代理里有哪些
代理可能包含下面一个或多个:
- 策略(Policy):代理的行为函数
- 值函数(Valut function):每个状态或者动作有多好
- 模型(Model):代理对环境的表示
其实值函数包括状态值函数$V(s)$和动作-状态值函数$Q(s,a)$,后面的章节会讲到
策略(Policy)
- 代理的行为函数
- 从状态到行为的映射
- 确定性策略:$a = \pi(s)$
- 不确定性策略:$\pi(a \mid s) = P[A_t = a \mid S_t=s]$
比如迷宫的例子中,策略指的是在每个位置到动作的映射,比如下图是确定性策略:
值函数(Value function)
- 值函数是对未来奖励的预测函数
- 用来评估状态的好坏
比如迷宫的例子中,函数值指的是每个状态的好坏,如下图。

我们可以看到左下角的函数值偏小,直观来看,是因为这些位置离出口很远。
模型(Model)
- 模型是用来预测环境接下来会怎样,主要包括状态转换和奖励
- $P$预测下一个状态
-
$R$预测下一个即时的奖励,例如
比如迷宫的例子中,模型中的状态转移就很特殊,因为它的转移是很确定性的,$P_{(2,1)\rightarrow(2,2)}^{向右} = 1$,其他的例子中可能在某个状态执行某个动作后,他可能到达状态1,也可能到达状态2;模型中的奖励也很特殊,$R_{s}^{a} = -1$,从任何状态,执行动作后转移到新状态,奖励都是-1,前面提到过.
代理的分类
根据代理里那三个部件的有无来分类,根据不同的准则有不同的分类方法,不同类别之间错综复杂,这里展示两种。
分类方法一,根据有无策略和值函数:
-
基于值的
- 没有策略(或者是隐示的)
- 有值函数
-
基于策略的
- 有策略
- 没有值函数
-
Actor Critic(不知道中文怎么讲)
- 有策略
- 有值函数
分类方法二,根据有无模型:
-
无模型的
- 策略或者值函数(或者同时都有)
- 没有模型
-
有模型的
- 策略或者值函数(或者同时都有)
- 有模型

学习(Learning)和规划(Planning)
我们在序列决策制定的时候有两个基础的问题:
-
强化学习:
- 环境模型起初是不了解的
- 代理通过与环境交互来了解环境或者说获得反馈状态和奖励
- 代理不断改善它的策略
-
规划:
- 环境模型是已知的
- 代理使用模型来执行计算(没有任何与环境的交互,因为我知道我执行动作后,状态的转移和奖励,所以就没必要交互了)
- 代理不断改善它的策略
比如迷宫的例子,学习问题是什么呢?指的是我们不知道每个状态下执行每个动作后的奖励,同时不知道在位置(2,1)执行向右后到达哪个位置,只有通过不断的交互,来观察反馈,通过这些交互的数据或者说是经验来不断提升我的策略。而规划问题是什么呢?就是我知道状态转移和奖励,那我直接根据这些来计算,从而不断的规划出一条最优的策略。
探索(Exploration)与利用(Exploitation)
- 强化学习是实验和试错学习
- 代理应该从他的经验中来学习一个好的策略
- 同时,在实验的过程中不能付出太大代价
- 探索就是发现更多的信息
- 利用就是利用以及的信息来最大化奖励
- 探索和利用同样重要
探索和利用的例子:
-
餐馆选择
- 利用是去你最喜欢的餐馆
- 探索是尝试一个新的餐馆
-
…
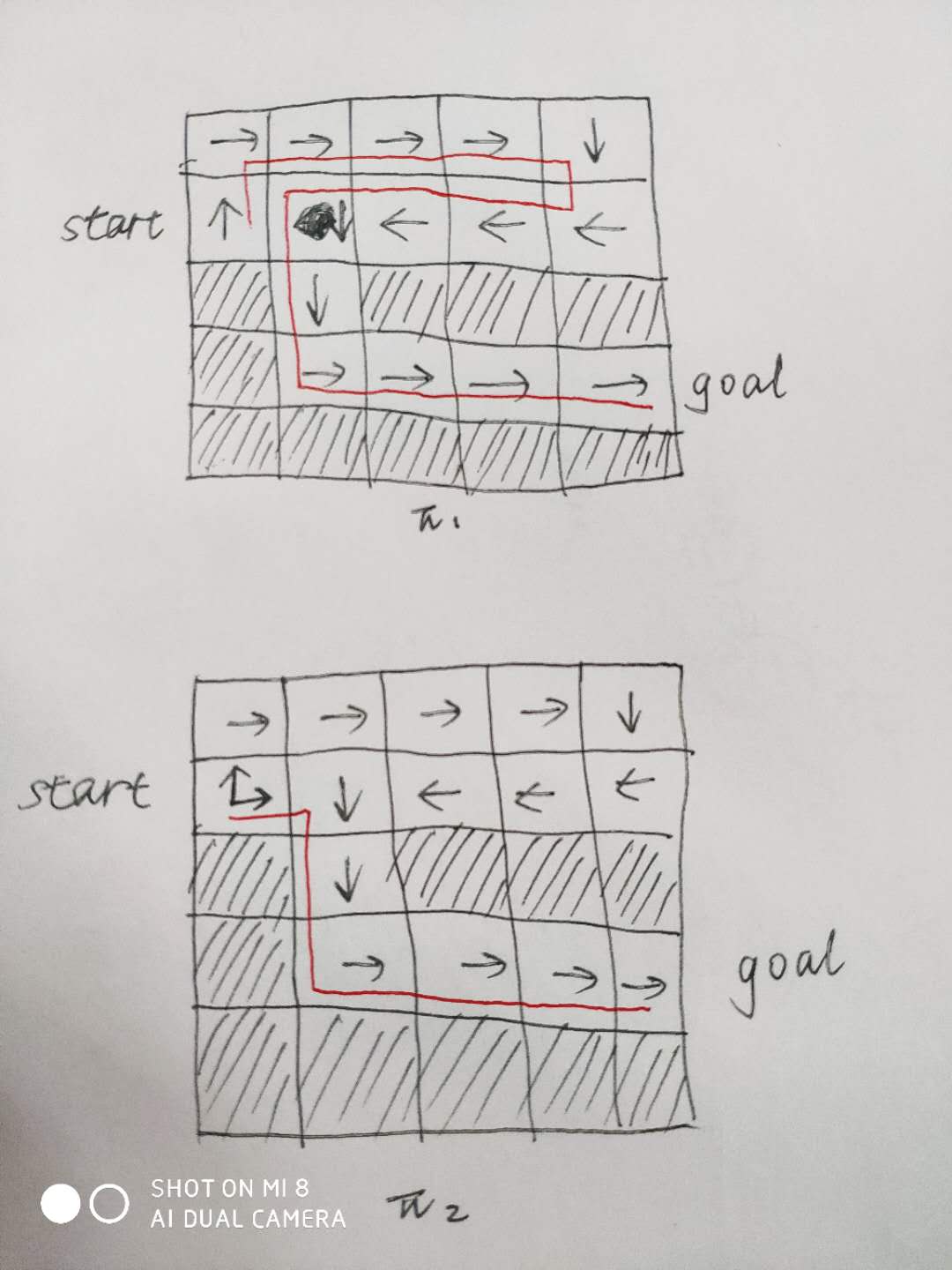
比如在迷宫的例子中,开始的迷宫比较特殊只有一条路线,不能说明问题,这里我手绘一个地图来说明探索和利用的重要性,如图所示。策略1明显只找到了一条较远的路线,这就是没有探索的原因,在位置(2,1)处,采用确定性策略向上,可能是在交互的过程中,先从上面走,得到了奖励,然后就一直向上,从而得到次优的策略。那我们怎么加入探索,一般都是将策略修改为不确定性策略,比如策略2,在(2,1)位置,有概率向上,也有概率向右,那么总会找到线路2,尝到甜头后,因为线路2比线路1更好,最终在位置(2,1)出的策略会修改为向右。这也是常用的方法,在交互过程中选择动作时采用不确定性策略,至于具体过程和理论,后面的章节会介绍。
预测(Prediction)和控制(Control)
预测:给定一个策略,评估未来的奖励
控制:找到最好的策略,来优化未来的奖励
比如迷宫的例子中,预测就是给定一个策略,比如手绘图中的策略1,我们评定这个策略有多好;那么控制就是我们要优化策略1,找到最好的策略,比如我们通过策略迭代的方法,先评估策略1有多好,然后改善策略,然后评估新的策略,这样迭代,直到得到最优策略。后面会讲到。